

机器学习模型已经绕过了使用波函数或密度泛函理论(DFT)计算来确定电子密度的需要。它将允许化学家快速确定依赖于大型系统的电子密度的性质,如范德华力、卤素键和C-H -π相互作用。这些非共价相互作用可以深入了解主-客体体系的结合或反应途径中有利的对映体,其中中间体和过渡态可能通过微妙的吸引而稳定。
电子密度分布是计算化学家最强大的工具之一。从电子密度可以确定电荷、偶极子和静电相互作用能等性质。准确地解释这些因素对于许多量子化学技术(如计算红外强度或确定非共价相互作用)的预测能力至关重要。
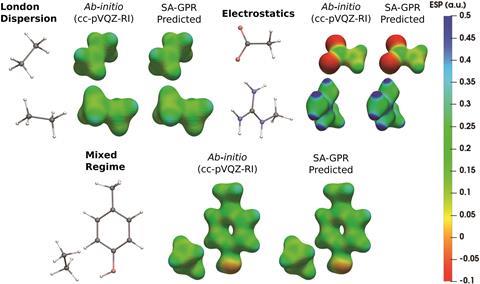
对于使用传统波函数或DFT方法的大型系统,计算电子密度具有挑战性和耗时。为了克服这个问题,克Corminboeuf,米歇尔Ceriotti和瑞士联邦理工学院(EPFL)的同事开发了一种机器学习模型,可以仅从原子坐标预测电子密度。团队成员阿尔贝托·法布里齐奥(Alberto Fabrizio)解释说:“这项突破是能够在不需要任何量子化学计算的情况下,最多在几分钟内准确预测复杂分子的电子密度。”
“我认为这是一种非常有趣的方法,无论是在预测误差方面,还是在小型和大型系统的可转移性方面,”评论道娜塔莉Fey他在英国布里斯托尔大学研究计算无机化学。
量子技巧,更好的机器学习
机器学习模型依赖于一个庞大的小分子二聚体训练集。这些二聚体的电子密度由基集表示,类似于在正常的计算化学计算中使用的基集。提高预测电子密度的准确性背后的技巧是使用为单位分辨率方法设计的辅助基集——一种有助于加快两个电子积分计算的近似。“与他们以前的工作相比,这项工作的关键进步在于,研究人员现在引入了辅助函数,以有效地参数化要预测的密度,”评论道马库斯苍鹭”他是苏黎世瑞士联邦理工学院的理论化学家。
Corminboeuf解释说:“标准基集被构造成尽可能接近波函数,而在单位分辨率近似内的辅助基集被设计成模拟单电子密度。”通过使用这些辅助基集,预测密度的误差减小到0.5%以下,远比cc-pVDZ等更常用基集的10%误差更准确。
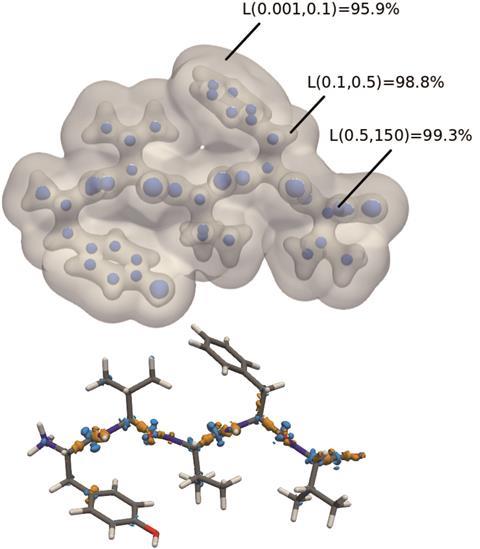
一旦机器学习代码在小二聚体的密度泛函计算电子密度上得到训练,就能够准确预测化学性质不同的、更大的系统的电子密度。与DFT计算相比,77个原子多肽脑啡肽的电子密度被成功预测在1.4%以内,而在一系列8个大多肽中,平均误差仅为1.5%。这种电子密度的实现速度远远快于标准DFT方法,可以更快地获得所有重要的电子密度,并进一步深入了解这些大型多肽中的非共价相互作用。
然而,Fey指出,当前模型的“短视”仍然是一个问题。这是指将分子表示为4Å宽原子中心环境的机器学习模型。因此,长距离的相互作用不能被完全捕获。
科米伯夫提出了一个可能的解决方案,他指出:“这个问题可以通过改变我们描述当地化学环境的方式来解决。”为了对非局部信息进行编码,人们可以制定框架,以潜在的形式表示环境,集成在所有空间中。“目前,新开发的机器学习模型将允许大量快速预测可能性,只要原子坐标可用,无论是来自x射线晶体学还是经典的分子动力学模拟。”





暂无评论