



工作流需要映射到反应表示stereocontrolling步骤的活化能
瑞士的科学家们已经开发出一种机器学习方法,可以确定反应的选择性催化了复杂organocatalysts。这种机器学习技术的强劲表现的关键是一个聪明的技巧,避免耗时的计算,通过一个知情的选择的分子描述符,反应表征和工程特性。

开发新的催化剂是至关重要的,以确保更快、更多的选择和更可靠的反应。的实验,大规模筛查仍然昂贵的人力资源、时间和设备的需求,”解释道西蒙Gallarati,从瑞士联邦理工学院洛桑(EPFL),谁领导的一项研究。”从计算的角度来看,数以百计的催化系统上运行的计算仍然是一个繁重的工作,与标准方法的选择性,实现准确的预测是一个非常艰巨的任务。这是由于传统的计算方法需要确定过渡状态,导致不同的对映体。
克里斯蒂娜•特鲁希略,他并没有参与这项研究,研究的计算设计organocatalysts在都柏林三一学院,爱尔兰说,计算及其在手性反应的过渡状态通常非常耗时,并且敏感的错误。“小错误可能导致相反的预测对映体的观察实验。在这个意义上,机器学习方法,在一般情况下,提供一个可选择的解决方案来克服当前的有关计算成本的挑战。
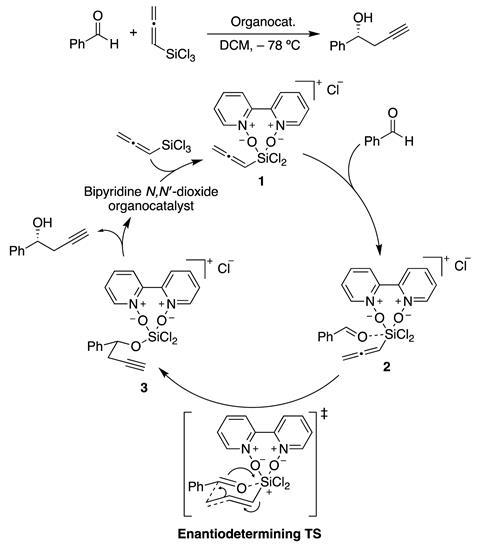
Gallarati和他的同事们调查如果机器学习方法可以用来确定构型,它起源于的相对活化能(R)和(年代)配体enantiodetermining过渡的配置状态,organocatalytic propargylation涉及不对称醛和丙二烯的反应和结果在一个新的手性中心。然而,机器学习模型并非没有并发症。原则上,我们可以满足机器学习模型信息未知的催化剂,其三维结构的形式,在几秒内获得选择性的一个预测,“Gallarati说。不幸的是,催化剂的选择性是一个非常困难的数量与机器学习模型预测准确。”
克服这个挑战本文针对预测的团队必须选择适当的表示propargylation反应,然后微调他们的模型嗅出结构噪声的基本特性。澳门万博公司这使得机器学习算法的训练来确定竞争激活能量(R)和(年代)通路可以被转换到对映体过量。
的好能力提出了战略预测能量差异不仅仅是非凡的,”评论玛丽亚Besora使用计算方法,研究催化·罗维拉我大学Virgili在西班牙。
定制的反应表示
知道的成本计算对映体过渡状态是具有挑战性的,欧洲职业足球联盟团队探索使用中间体的反应过渡态的表征训练机器学习模型。开始从过渡状态数据库由史蒂文·惠勒德克萨斯A&M大学和他的同事在美国,欧洲职业足球联盟团队中间体的过渡态计算使用DFT内在反应坐标计算。这些中间体被转化为分子表征——一个版本的重要的信息分子,通过机器学习算法可以被理解。分子表示的不同物理参数有机的集合,基于文本的表示和chemoinformatics-type描述符,“Gallarati说。团队选择Slatm,即伦敦和Axilrod-Teller-Muto谱,因为这表示可以编码三维分子结构。
下一步涉及发现拆分反应步骤的表示,可以用于训练和预测激活能量。为此,团队的差异进行了探讨中间的Slatm表示“包含所有信息的结构特点改变了在反应步骤,消除那些保持不变,“根据Gallarati。澳门万博公司这个的优点是反应的一个合适的表示和减少机器学习算法处理的数据量。最后,团队应用特性工程涉及交叉验证的步骤来提高精度和减少噪音与反应表示,大大减少了所需的数据量。
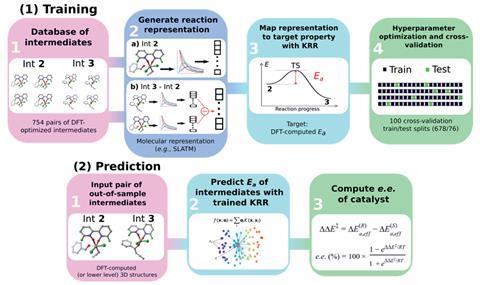
因此,机器学习模型预测了活化能,因此本文针对,关于环N,N“-dioxides,没有培训数据库的一部分,仅从中间结构。此外,机器学习模型阐明构型确定过渡状态的关键特性在不对称propargylation反应,识别π-stacking和CH /π交澳门万博公司互作为关键的主题。
然而,特鲁希略所指出的一个局限是,大量的中间体,超过1000,需要训练算法,反应相当具体的调查。然而,在未来有可能对机器学习解决方案扩展到更广泛的系统。我认为使用机器学习模型领域的organocatalysis在不久的将来将会增加。在这种背景下,我认为这是一个有前途的发展,但大部分时间需要进一步概括,特鲁希略说。
”策略并非基于预测的对映体过量但不同的能源打开了门其他化学问题的适用性,并预测对映体选择性扩展到预测的更复杂的问题时发挥作用,”言论Besora。的原则上,我们的方法可以用来开发一个机器学习模型预测的选择性催化系统,”评论Gallarati”提供了一个足够大的结构性信息用于培训。






还没有评论