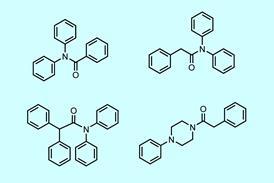



将机器学习与计算推导的描述符相结合,使科学家能够仅使用少量实验数据点就找到一类特殊催化剂的新例子。团队由Franziska Schoenebeck来自德国亚琛工业大学的研究人员开发了一种工作流程,识别了21种磷化氢配体,这些配体可以在更常见的钯(0)和钯(II)物种上形成具有一定几何形状和空气稳定性的双核钯(I)配合物。1
“与大多数常用的钯基催化剂相比,这些二聚体是非常有前途的催化剂,具有明显的反应性,”评论道托拜厄斯Gensch来自德国柏林工业大学,他没有参与这项研究。“然而,它们的化学性质还没有被很好地理解,因为它们的合成是不可预测的,配体对二聚体稳定性的影响也是未知的。他说,新的方法使研究人员能够预测稳定钯(I)二聚体的配体,并合成这些复合物的几个新例子。
发现有效的催化剂是许多化学创新的关键,但不同的物种具有不同的活性和选择性,因此找到合适的化合物是具有挑战性的。“从原则上讲,准确预测催化剂的物种形成,需要精确了解在特定条件下可以形成的所有物种及其相对能量——这是一项艰巨的任务!”指出Marc-Etienne Moret他是荷兰乌得勒支大学的有机金属化学家。
这就是为什么化学家通常依赖于反复试验,测试他们认为可行的配体。“科学家们还根据配体的性质绘制了分类图;这可以帮助他们从视觉上识别有潜力的候选人,”莫雷特补充道。但在某些情况下,这些方法不起作用。他说,新的结果表明,机器学习可以成功地预测配体,而直觉和视觉检查都无法成功。“这可以通过在实验室中制造和广泛测试之前确定有前景的目标来加速新催化剂的开发。”
科学家们首先使用一种算法根据348个配体的一般性质筛选它们,然后通过引入从密度泛函理论计算中获得的特定问题数据来进行额外的聚类。这种策略允许他们将一个大数据集分成更小的相似度更高的子集,根据手头的问题量身定制。随后,该团队通过实验验证了一些预测的配体,其中包括一种以前从未合成过的配体,并利用它们制造了新的钯(I)二聚体。
Gensch指出,该系统仅使用5个实验数据点就可以识别新的配体。他说:“其他机器学习方法,如回归建模,需要更多的数据作为输入。”“能够处理如此少的数据,是通用配体数据库和信息丰富的问题特定描述符结合使用的结果,再加上简单而强大的两阶段聚类方法。”
莫雷特说:“该算法预测的准确性非常高。”“这表明配体可能永远不会被测试。这种方法可能有助于解决许多相关问题,这些问题存在经验或计算数据,但还没有形成直观易懂的图像。”
参考文献
JA Hueffel等,科学, 2021, doi:10.1126 / science.abj0999





暂无评论