



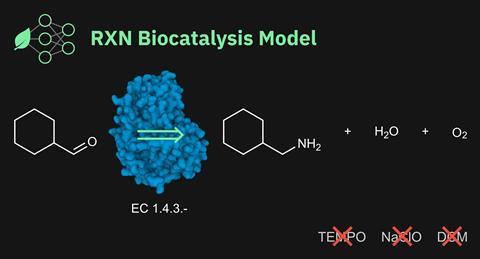
研究人员首次整合酶使用机器学习retrosynthetic化学反应计划。使用数据从四个公共生化反应数据库团队从IBM研究欧洲在瑞士教RXN化学工具预测反应结果和计划使用酶化学合成。
这种相对较小的数据集的60000多个反应使RXN正确预测产品从给定enzyme-mediated反应在其第一次尝试近一半的时间。它可能还计划出一个绿色retrosynthetic路线使用酶,使所需的目标化学几乎40%的时间。它甚至能够纠正一些错误的原始数据集。
推进的关键是证明机器学习驱动反应计划可以扩展酶,IBM研究欧洲的说丹尼尔Probst。证明这确实有效,即使这些有限的数据集,是中心点,”他强调。
Probst和他的同事们正试图使化学工业更清洁和更可持续。生化过程可以清理传统使用有毒溶剂的化学过程,高温和压力,并产生大量的浪费。许多公司已经采用酶催化更快、更清洁的反应,但是可用的方法尚未合成有机化学一样多才多艺。
RXN系统使用IBM的分子变压器平台,预测的结果反应由用户输入。的反应计划还可以建议路线所需的分子。分子变压器使用自然语言处理技术还发现在应用自动翻译和语音助手。
延长化学词汇
IBM研究欧洲研究者改编这个人工智能(AI)方法从化学专利数据,提取反应规则,这样分子变压器“讲化学”。看起来学习分子和互动,Probst解释说,专门为化学结构学习过程符号叫做微笑。
去年,IBM与伯尔尼大学的合作,扩大词汇量,酶反应。这种方法训练神经网络文本描述的酶,而不是其确切的分子结构。它只能预测反应的结果,而不是retrosynthetically计划路线。
直到最近,没有自动化的方式来计划酶反应。然而在2021年,威廉Finnigan曼彻斯特大学公布了和他的同事们RetroBioCat。在最初的论文描述它,RetroBioCat包括99手工编码的反应。手动定义每个反应规则可能会休息一天,Probst估计,但应用机器学习得更快。最初IBM研究欧洲的工具适应酶两到三个月,然后Probst说数据驱动方法可以扩大手工没有定义新的规则。问题是是否能找到相同的规则从人类相同的数据,”他补充道。
Finnigan调用直接从数据库中,而不是进入学习规则“非常令人兴奋”。然而,他知道没有好的数据库综合利用酶的化学物质。“我相信IBM工具对准几个数据库有更多的专注于酶代谢的功能,“Finnigan告诉manbetx手机客户端3.0。作为RetroBioCat更直接地关注酶合成这两种方法是互补的,Finnigan说。“在一天结束的时候,这些工具应该寻求增加科学家的能力提出新的想法和建议。
IBM研究欧洲目前正在微笑的理解这方面数据RXN模型使用最使其决策。这可能使Probst和他的同事们计算出哪些规则形式的生化知识,很难知道当使用机器学习的东西——通常被称为“黑盒”问题。
引用
D Probst等,Commun Nat。,2022,DOI:10.1038 / s41467 - 022 - 28536 - w






还没有评论