

科学家们已经在用于训练计算机辅助合成的机器学习模型的数据集中发现了人类的偏见。1他们发现,在一个小的随机反应样本上训练的模型比在更大的人类选择数据集上训练的模型表现得更好。结果表明,在为化学家开发计算机程序时,包括人们可能认为不重要的实验结果的重要性。
机器学习模型在化学合成中是一个有价值的工具,但它们是根据文献中的数据进行训练的,其中积极的结果更受欢迎,而黑暗反应(尝试过但没有成功的实验)通常被排除在外。“包含这些失败对于生成预测性机器学习模型是至关重要的,”他说约书亚Schrier他所在的团队研究了胺模板金属氧化物的水热合成,并发现人们对反应参数的选择会将偏差引入文献中。
施里尔说:“我们考虑了额外的黑暗反应——一类人类甚至都不会尝试的反应,不是因为科学或实际原因,只是因为是人类做出了决定。”“我们发现化学家在计划新实验时倾向于墨守陈规,而社会线索会加强这一点。”有一种随大流的倾向,正如文献中的先例所定义的那样。他说,这导致在实验数据集中,一些试剂和反应条件被系统性地夸大了。“我们在晶体学数据库和实验室笔记本上收集的数字化暗反应中都找到了证据。”
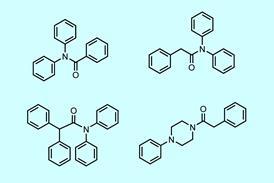
研究人员评估了剑桥结构数据库中沉积的5000多个胺模板金属氧化物结构,发现17%的已知胺反应物(70个“流行”分子)出现在79%的报告结构中,而剩下的83%(345个“不流行”分子)只出现在21%的结构中。他们还分析了未发表的硼酸钒热液反应的实验记录暗反应项目并在pH值和胺量上发现了类似的偏差。
“我们故意拒绝了这些探索性反应的标准方法,从而消除了这种偏见,”他说亚历山大Norquist他也参与了这项研究。他指出,当使用“不受欢迎的”胺时,反应性能没有差异。“我们创建了两个机器学习模型。一个使用有偏见的数据,另一个使用随机实验。随机实验得到的模型更强、更好。在用看不见的试剂进行的实验室测试中,它能够更成功地预测新的反应,并发现新的化合物,而这些化合物将完全被基于人为偏差数据训练的模型所遗漏。”
李·克罗宁英国格拉斯哥大学的教授说,研究结果很有趣,但并不令人惊讶。他说,所有的项目都有偏见,关键是要承认。康纳绿青鳕美国麻省理工学院(Massachusetts Institute of Technology)的教授对此表示赞同。有人可能会说,作者把一种偏见换成了另一种。即使在“随机”实验中,他们也必须指定他们感兴趣的参数空间的概率分布,”他说。克罗宁补充说,这项研究考虑了晶体的热液形成,这是非常广泛和连续的。他说:“这并不适用于不连续的事物,比如新型反应。”
Sorelle fiedl的用于检查电子邮件地址哈弗福德学院的教授也参与了这项研究,他说,人们正在开发技术来鼓励机器学习的公平性。她认为这种方法将是这项工作的一个有趣的扩展。但科利认为,偏见问题可能仍然存在。他说:“从算法上选择实验是减少人类偏见影响的一个好方法,但选择算法和确定其目标仍然是非常主观的任务。”
参考文献
1 X甲等,自然, 2019,573, 251 (doi:10.1038 / s41586 - 019 - 1540 - 5)




暂无评论