
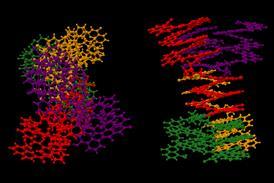



llm可能超越Alphafold,但目前很难确定简单的化学结构
人工智能的边缘是巨大的吗?巴斯在过去的几个月里,由于释放改善“大型语言模型”(llm)如OpenAI GPT-4 ChatGPT的继承人。开发作为语言处理工具,这些算法反应如此流利和自然,一些用户确信他们交谈的一个真正的智慧。一些研究人员认为,llm超越传统的深度学习人工智能方法通过展示紧急人类思维的特点,如心理理论与自治和其他代理属性的动机。澳门万博公司其他人认为,所有的令人印象深刻的功能,llm保持练习找到相关性,不仅没有任何的感觉,还语义理解世界的主旨是谈论——显示,例如,在llm仍然可以让荒谬不合逻辑的错误或发明错误的事实。危险正说明时,Bing的搜索chatbot悉尼,合并ChatGPT,威胁要杀死一名澳大利亚研究员和试图打破了婚姻的纽约记者在表达爱。
AI和复杂性专家梅勒妮米切尔和大卫·科莱考尔圣达菲研究所的我们,与此同时,建议第三种可能:llm拥有一种真正的理解,但我们尚不了解自己,这是截然不同于人类思维。1
尽管他们的名字,llm不仅是有用的语言。像其他类型的深度学习方法,比如DeepMind工作背后的算法AlphaFold我,他们庞大的数据集变量之间的相关性,经过一段时间的培训,使他们能够提供可靠的应对新的输入提示。所不同的是,llm使用神经网络架构称为变压器,在神经元的参加更多的一些连接比别人。这个特性增强llm生成自然文本的能力,但也可能使他们能够更好地应对输入训练集之外的——因为,一些人声称,算法推导出一些潜在的概念原则,所以不需要告诉尽可能多的训练。
这些网络在很大程度上是不透明的内部运作
梅勒妮米切尔和大卫Krakauer圣达菲研究所
这表明llm也可能比传统的深度学习的时候做得更好应用于科学问题。的含义最近的一篇论文,应用LLM推断蛋白质结构的“AlphaFold问题”纯粹从序列。2(我愿称之为蛋白质折叠问题,因为这是有点不同。)Alphafold的能力已经被正确地称赞,甚至还有一些理由认为它可以推断的一些特性的潜在能源景观澳门万博公司。但亚历山大当元AI在纽约和他的同事们说,他们家族的变压器蛋白质语言模型统称为ESM-2,和一个模型称为ESMFold来源于它,做得更好。语言模型是快了两个数量级,需要更少的训练数据,并且不依赖于所谓的多序列比对的集合:序列与目标结构密切相关。研究人员的模型在MGnify90大约6.17亿个蛋白质序列数据库策划由欧洲生物信息学研究所。超过三分之一的产量高信任度的预测,包括一些没有先例实验确定结构。
作者声称,这些改进性能确实因为这样llm有更好的概念问题的‘理解’。正如他们所说的语言模型内部进化模式与结构的——这意味着它可能打开的深视图的自然多样性蛋白质”。大约有150亿的参数模型,尚不容易提取与任何确定性的内部表征的改善性能。但这样的索赔,如果支持,使llm更令人兴奋的做科学,因为他们可能使用甚至帮助揭示底层物理原则。
作者声称,这些改进性能确实因为这样llm有更好的概念问题的‘理解’。正如他们所说的语言模型内部进化模式与结构的——这意味着它可能打开的深视图的自然多样性蛋白质”。大约有150亿的参数模型,尚不容易提取与任何确定性的内部表征的改善性能:“很大程度上这些网络的内部运作不透明,”米切尔和科莱考尔说。但这样的索赔,如果支持,使llm更令人兴奋的做科学,因为他们可能使用甚至帮助揭示底层物理原则。
可能还有一段路要走,然而。当化学家Cayque蒙泰罗卡斯特罗Nascimento,安德烈·席尔瓦的皮门特尔在巴西里约热内卢天主教大学做ChatGPT一些基本的化学挑战,如复合名称转换成微笑化学表征,结果喜忧参半。算法正确确定对称点群的十个简单的分子,做了一个公平的工作预测11个不同的水溶性聚合物。但它似乎不知道之间的区别烷烃和烯烃,或苯和环己烯。与语言应用程序一样,得到好的结果可能部分取决于提出正确的问题:现在“促使工程”的一个新兴领域。话又说回来,问正确的问题无疑是最重要的一个任务进行任何形式的科学。
引用
1 M米切尔和D C科莱考尔透露,2023年,arXiv:2210.13966
2 Z林et al。,科学,2023,379年,1123 (DOI:10.1126 / science.ade2574)





还没有评论